建立Scrapy專案
Scrapy框架安裝完成後,接下來,就可以建立Scrapy專案來開發網頁爬蟲。本文以新聞網頁爬蟲專案為例,在桌面先建立一個「news_scraper」資料夾,接著,開啟Visual Studio Code,打開「news_scraper」資料夾,在Terminal視窗中即可利用以下的指令來建立Scrapy專案:
$ scrapy startproject 你的專案名稱 .
執行結果
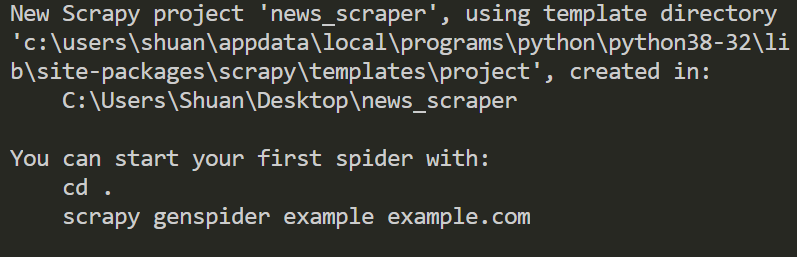{kind=link}
Scrapy專案結構
這時候,可以在「news_scraper」資料夾中看到Scrapy專案的檔案結構:
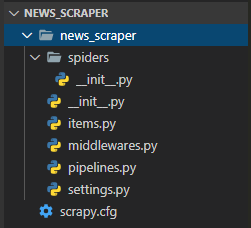{kind=link}
其中各個檔案的功能說明如下:
- spiders資料夾:用來存放Python網頁爬蟲程式碼的地方。
- items.py:定義想要爬取或儲存的資料欄位。
- middlewares.py:定義「spiders與引擎(ENGINE)中間件」及「引擎(ENGINE)與下載器(DOWNLOADER)中間件」。
- pipelines.py:定義items資料的後續處理,像是清理、儲存至資料庫或檔案等。
- settings.py:Scrapy專案設定檔。
- scrapy.cfg:Scrapy專案部署設定檔。
在建立Scrapy專案時,可以看到如下圖的執行結果:
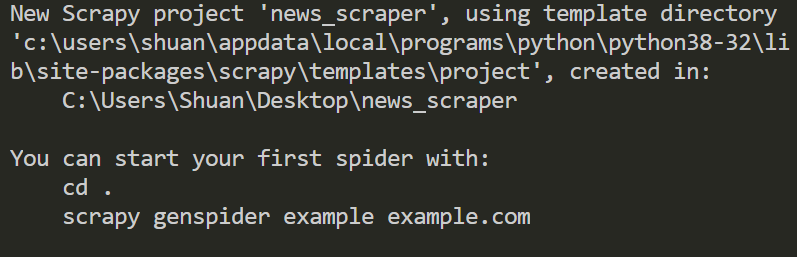{kind=link}
其中,提示了建立Scrapy網頁爬蟲的方法,也就是如下指令:
$ scrapy genspider 網頁爬蟲檔案名稱 目標網站的網域名稱
舉例來說,本文想要建立一個Scrapy網頁爬蟲,來爬取INSIDE硬塞的網路趨勢觀察網站的AI相關新聞,這時候,就可以開啟Scrapy專案,比照以上的指令來建立網頁爬蟲:
$ scrapy genspider inside www.inside.com.tw
執行結果
{kind=link}
成功建立Scrapy網頁爬蟲後,在專案中的spiders資料夾下,就可以看到多了一個inside.py檔案,如下圖:
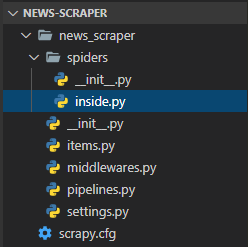{kind=link}
二、Scrapy網頁爬蟲架構
開啟spiders資料夾下的inside.py網頁爬蟲檔案,可以看到Scrapy框架幫我們產生了以下的內容結構:
- import scrapy
- class InsideSpider(scrapy.Spider):
- name = 'inside'
- allowed_domains = ['www.inside.com.tw']
- start_urls = ['http://www.inside.com.tw/']
- def parse(self, response):
- pass
其中,包含了以下三個屬性(Attribute)及一個方法(Method):
- name屬性:網頁爬蟲的名稱,在專案中必須是唯一的。
- allowed_domains屬性:目標網站的網域名稱清單。
- start_urls屬性:想要爬取的一至多個網頁網址清單。
- parse()方法:撰寫網頁爬蟲程式邏輯的地方,特別注意此方法名稱不得更改。
三、Scrapy網頁爬蟲執行方法
由於本文所要爬取的是INSIDE硬塞的網路趨勢觀察網站的AI相關新聞,所以在start_urls屬性的地方,修改為AI新聞的網頁網址,如下範例第7行:
- import scrapy
- class InsideSpider(scrapy.Spider):
- name = 'inside'
- allowed_domains = ['www.inside.com.tw']
- start_urls = ['https://www.inside.com.tw/tag/ai']
- def parse(self, response):
- pass
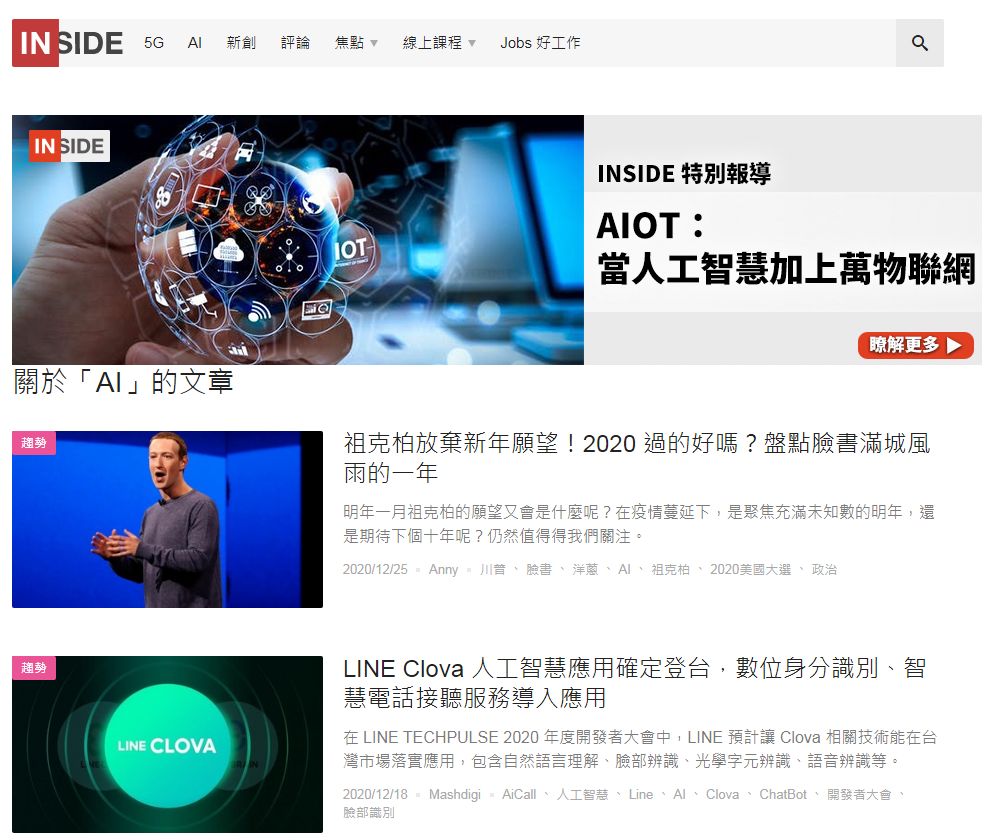
接下來,就可以在parse()方法(Method)中,撰寫網頁爬蟲的邏輯。而在開發之前,先來分析一下INSIDE硬塞的網路趨勢觀察網站的AI新聞網頁,如下圖:
{kind=link}
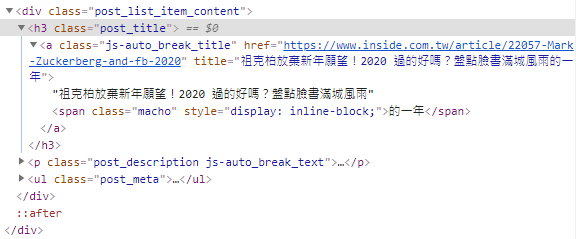
在新聞標題的地方,點擊右鍵,選擇「檢查」,可以看到HTML原始碼如下圖:
{kind=link}
從上圖可以看出來,利用<h3>標籤及它的「post_title」樣式類別(class),就可以定位到新聞標題的元素。
回到Scrapy專案中的inside.py檔案,在parse()方法(Method)的地方,利用Scrapy框架的定位元素語法,就可以來撰寫網頁爬蟲,這部分將會在下一篇文章和大家進行分享,本文先以BeautifulSoup模組(Module)為例進行示範,如下範例:
- import scrapy
- import bs4
- class InsideSpider(scrapy.Spider):
- name = 'inside'
- allowed_domains = ['www.inside.com.tw']
- start_urls = ['https://www.inside.com.tw/tag/ai']
- def parse(self, response):
- soup = bs4.BeautifulSoup(response.text, 'lxml')
- titles = soup.find_all('h3', {'class': 'post_title'})
- for title in titles:
- print(title.text.strip())
首先,需引用bs4模組(Module),在第11行將Scrapy引擎(ENGINE)回應的結果進行解析,接著,爬取網頁的所有新聞標題,並且透過迴圈把取得的每個新聞標題印出來。
完成後,在執行這個Scrapy網頁爬蟲之前,需設定User-Agent(使用者代理),簡單來說,就是瀏覽器的相關資訊,位於settings.py檔案,如下範例:
- #USER_AGENT = 'news_scraper (+http://www.yourdomain.com)'
預設是註解的狀態,所以,將註解取消並且加上User-Agent(使用者代理),如下範例:
- USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
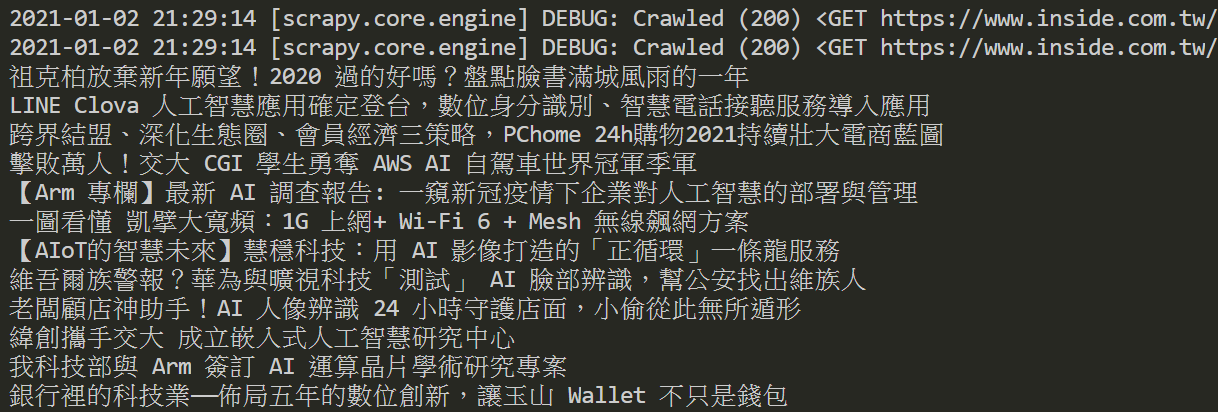
最後,就可以利用「scrapy crawl」指令,加上網頁爬蟲的名稱inside,來執行Scrapy網頁爬蟲,如下範例:
$ scrapy crawl inside
執行結果
{kind=link}
參考網站: https://www.learncodewithmike.com/2021/01/scrapy-create-spider.html